Research Projects
-
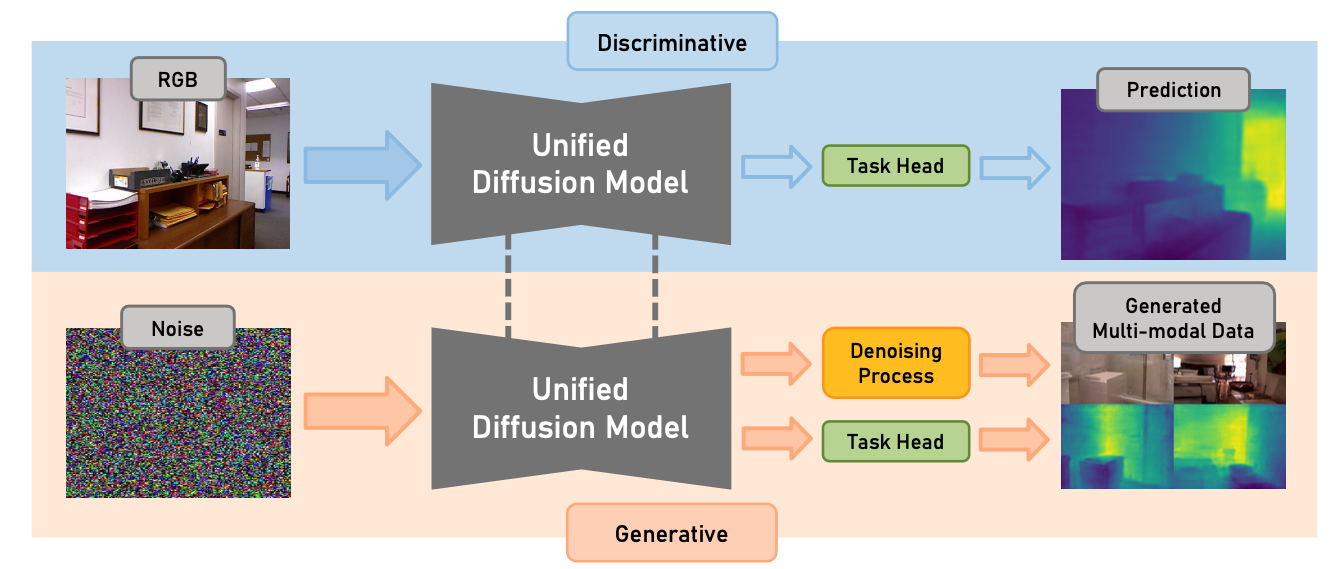
Diff-2-in-1: Bridging Generation and Dense Perception with Diffusion Models
Under review
Shuhong Zheng, Zhipeng Bao, Ruoyu Zhao,Martial Hebert, Yu-Xiong Wang -

ReferEverything: Towards segmenting everything we can speak of in videos
Under review
Anurag Bagchi, Zhipeng Bao, Yu-Xiong Wang, Pavel Tokmakov, Martial Hebert
-
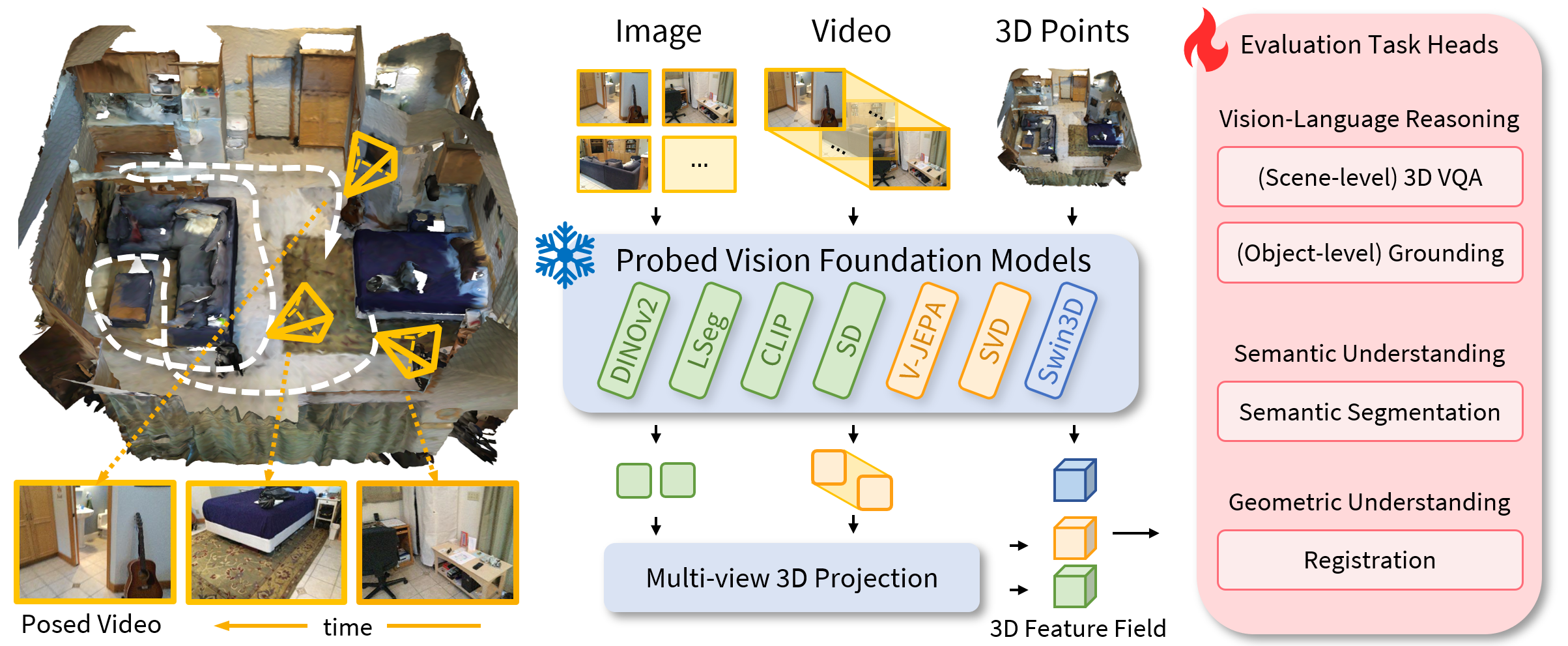
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
NeurIPS 2024
Yunze Man, Shuhong Zheng, Zhipeng Bao, Martial Hebert, Liangyan Gui, Yu-Xiong Wang
-
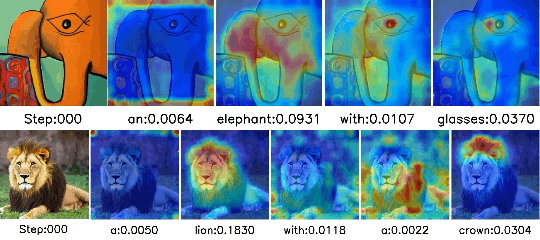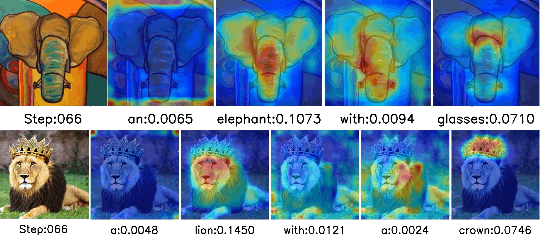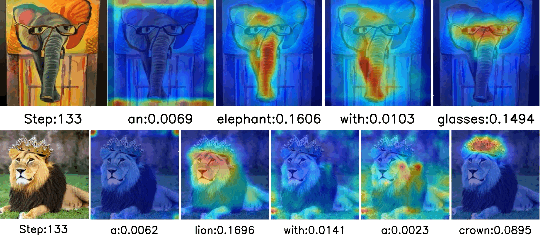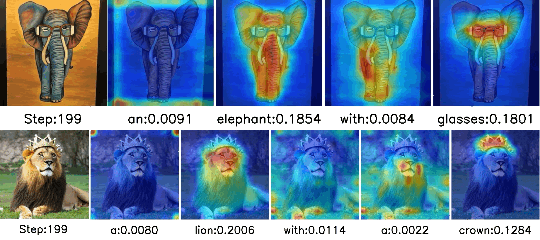
Separate-and-Enhance: Compositional Finetuning with Text-to-Image Diffusion Models
SIGGRAPH 2024
Zhipeng Bao, Yijun Li, Krishna Kumar Singh, Yu-Xiong Wang, Martial Hebert
-
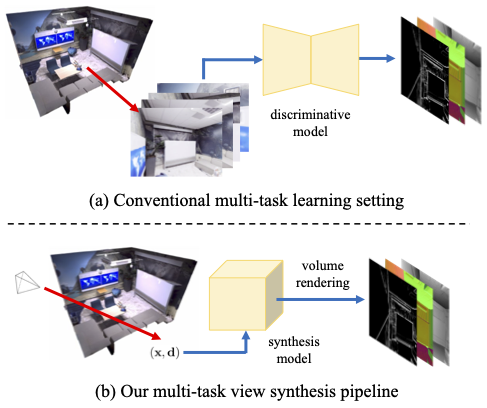
Multi-task View Synthesis with Neural Radiance Fields
ICCV 2023
Shuhong Zheng*, Zhipeng Bao*, Martial Hebert, Yu-Xiong Wang
-
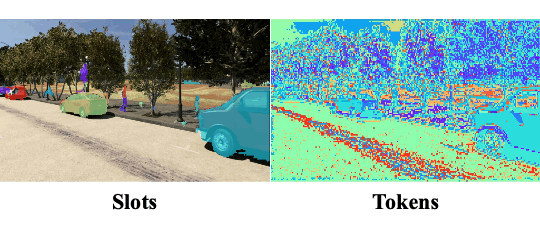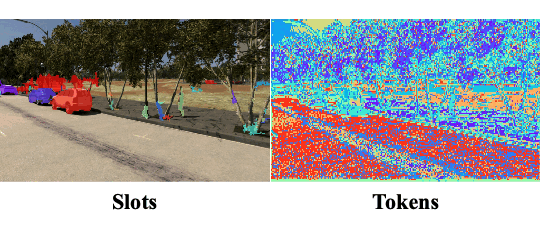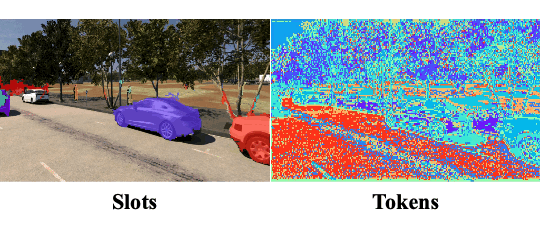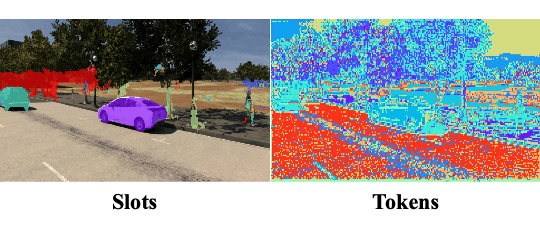
Objects Discovery from Motion-guided Tokens
CVPR 2023
Zhipeng Bao, Pavel Tokmakov, Yu-Xiong Wang, Adrien Gaidon, Martial Hebert
-
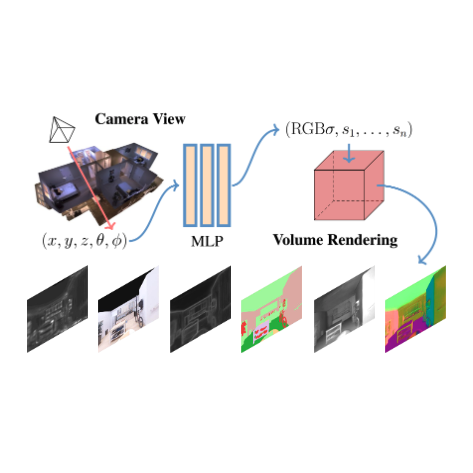
Beyond RGB: Scene-property Synthesis with Neural Radiance Fields
WACV 2023
Mingtong Zhang*, Shuhong Zheng*, Zhipeng Bao, Martial Hebert, Yu-Xiong Wang
-
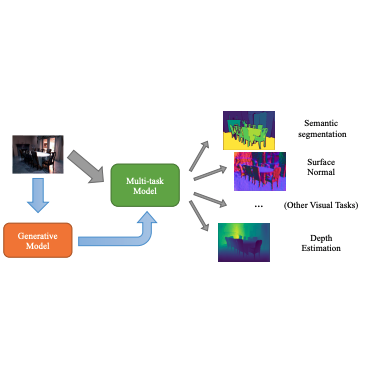
Generative Modeling for Multi-task Visual Learning
ICML 2022
Zhipeng Bao, Martial Hebert, Yu-Xiong Wang
-

Discovering Objects that Can Move
CVPR 2022
Zhipeng Bao*, Pavel Tokmakov*, Allan Jabri,Yu-Xiong Wang, Adrien Gaidon, Martial Hebert
-
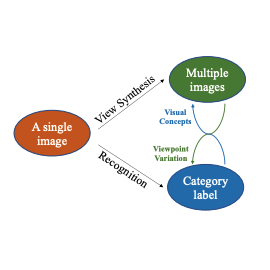
Bowtie Networks: Generative Modeling for Joint Few-Shot Recognition and Novel-View Synthesis
ICLR 2021
Zhipeng Bao, Yu-Xiong Wang, Martial Hebert
-

Single-Image Facial Expression Recognition Using Deep 3D Re-Centralization
ICCV 2019 Workshops
Zhipeng Bao, Shaodi You, Gu Lin, Zhenglu Yang
-

A Joint Method for Marker-free Alignment of Tilt Series in Electron Tomography
ISMB 2019
Renmin Han, Zhipeng Bao, Xiangrui Zeng, Tongxin Niu, Min Xu, Xin Gao